
Developers and creatives looking for greater control and privacy with their AI are increasingly turning to locally run models like OpenAI’s new gpt-oss family of models, which are both lightweight and incredibly functional on end-user hardware. Indeed, you can have it run on consumer GPUs with just 16GB of memory. That makes it possible to use a wide range of hardware – with NVIDIA GPUs emerging as the best way to run these sorts of open-weight models.
While nations and companies rush to develop their own bespoke AI solutions to a range of tasks, open source and open-weight models like OpenAI’s new gpt-oss-20b are finding much more adoption. This latest release is roughly comparable to the GPT-4o mini model which proved so successful over the past year. It also introduces chain of thought reasoning to deeply think through problems, adjustable reasoning levels to adjust thinking capabilities on-the-fly, expanded context length, and efficiency tweaks to help it run on local hardware, like NVIDIA’s GeForce RTX 50 Series GPUs.
But you will need the right graphics card if you want to get the best performance. NVIDIA’s GeForce RTX 5090 is its flagship card that’s super-fast for gaming and a range of professional workloads. With its Blackwell architecture, tens of thousands of CUDA cores, and 32GB of memory, it’s a great fit for running local AI.
Llama.cpp is an open-source framework that lets you run LLMs (large language models) with great performance especially on RTX GPUs thanks to optimizations made in collaboration with NVIDIA. Llama.cpp offers a lot of flexibility to adjust quantization techniques and CPU offloading.
Llama.cpp has published their own tests of gpt-oss-20b, where the GeForce RTX 5090 topped the charts at an impressive 282 tok/s. That’s in comparison to the Mac M3 Ultra (116 tok/s) and AMD’s 7900 XTX (102 tok/s). The GeForce RTX 5090 includes built-in Tensor Cores designed to accelerate AI tasks maximizing performance running gpt-oss-20b locally.
Note: Tok/s, or tokens per second, measures tokens, a chunk of text that the model reads or outputs in one step, and how quickly they can be processed.

NVIDIA
For AI enthusiasts that just want to use local LLMs with these NVIDIA optimizations, consider the LM Studio application, built on top of Llama.cpp. LM Studio adds support for RAG (retrieval-augmented generation) and is designed to make running and experimenting with large LLMs easy—without needing to wrestle with command-line tools or deep technical setup.
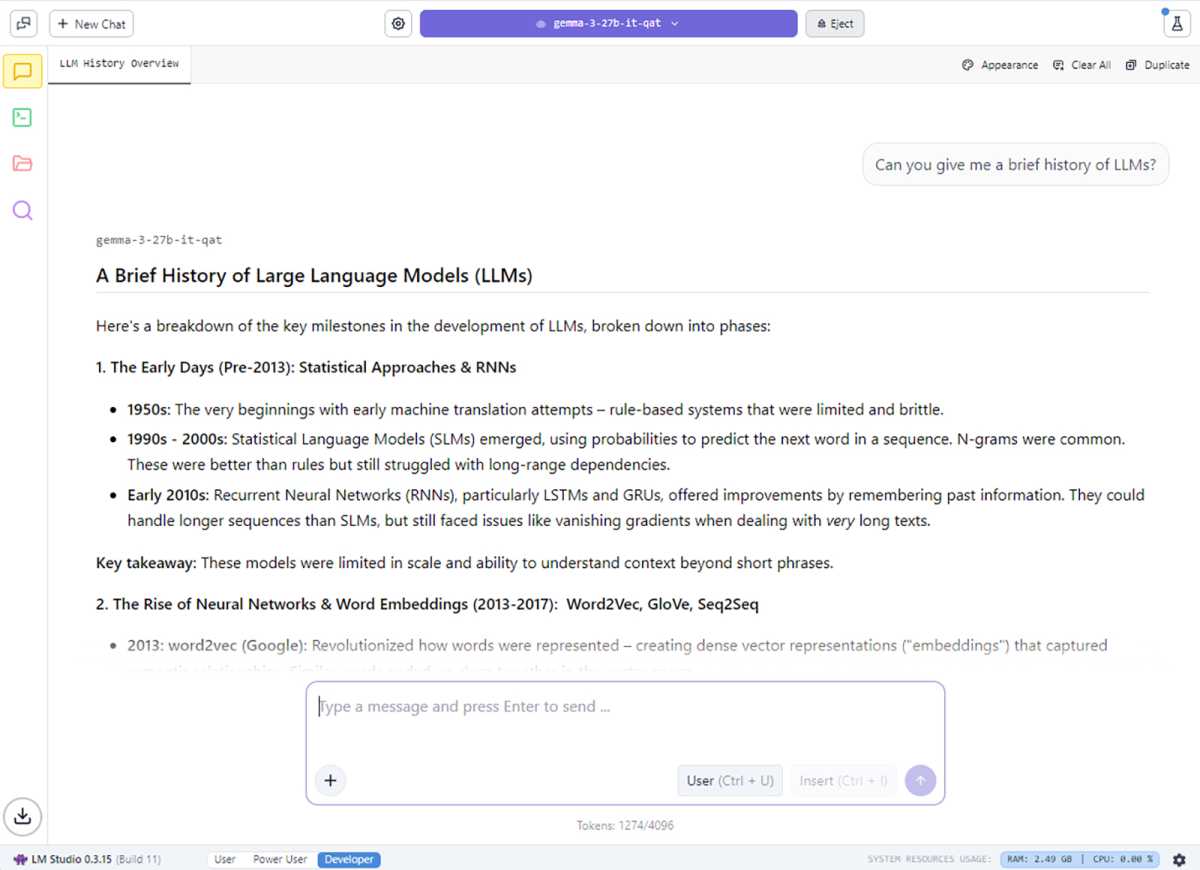
NVIDIA
Another popular open source framework for AI testing and experimentation is Ollama. It’s great for trying out different AI models, including the OpenAI gpt-oss models, and NVIDIA worked closely to optimize performance, so you’ll get great results running it on an NVIDIA GeForce RTX 50 Series GPU. It handles model downloads, environment setup and GPU acceleration automatically, as well as built-in model management to support multiple models simultaneously, integrating easily with applications and local workflows.
Ollama also offers an easy way for end users to test the latest gpt-oss model. And in a similar way to llama.cpp, other applications also make use of Ollama to run LLMs. One such example is AnythingLLM with its straightforward, local interface making it excellent for those just getting started with LLM benchmarking.
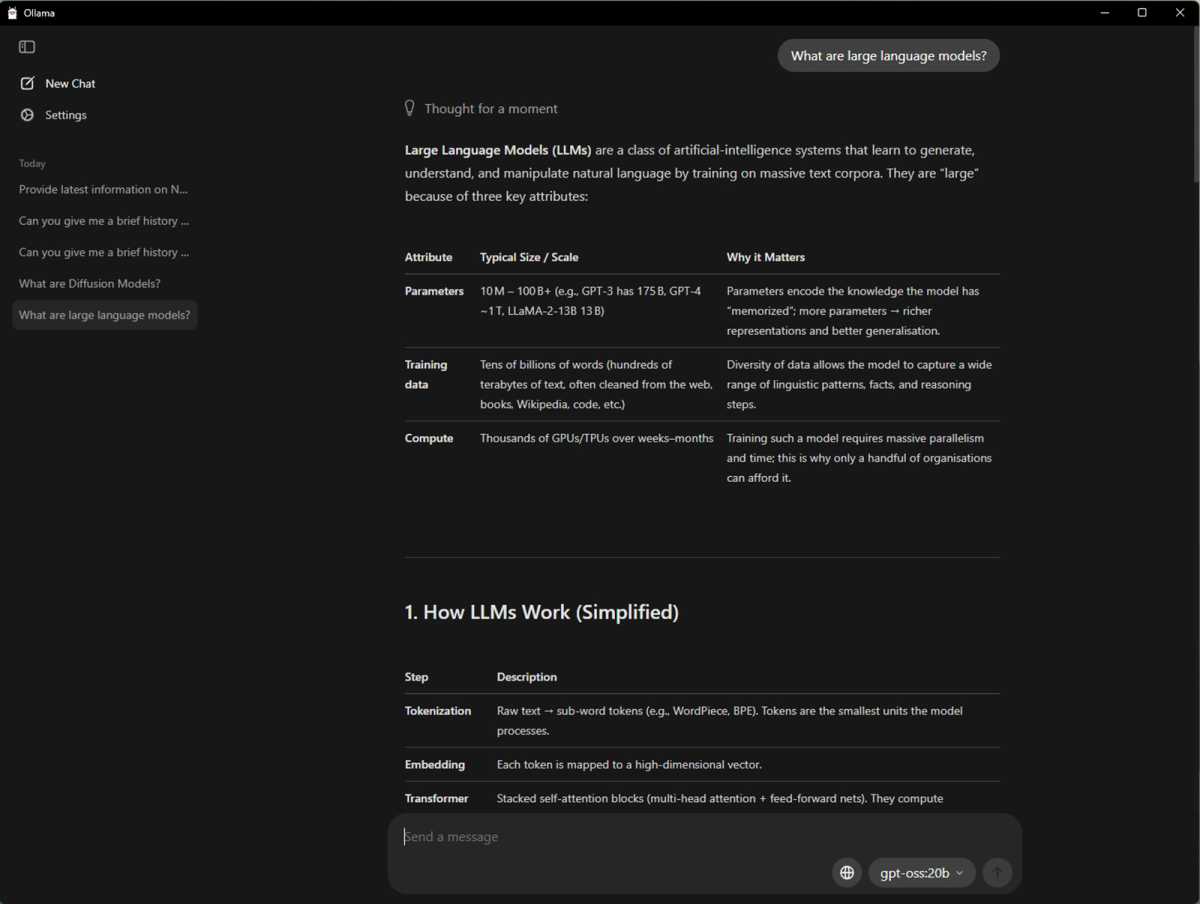
NVIDIA
If you have one of the latest NVIDIA GPUs (or even if you don’t, but don’t mind the performance hit), you can try out gpt-oss-20b yourself on a range of platforms. LM Studio is great if you want a slick, intuitive interface that lets you grab any model you want to try out and it works on Windows, macOS, and Linux equally well.
AnythingLLM is another easy-to-use option for running gpt-oss-20b and it works on both Windows x64 and Windows on ARM. There’s also Ollama, which isn’t as slick to look at, but it’s great if you know what you’re doing and want to get setup quickly.
Whichever application you use to play around with gpt-oss-20b, though, the latest NVIDIA Blackwell GPUs seem to offer the best performance.





